STOP MESSY DATA WRANGLING
Supercharge growth with Batch CSV automation
Code-free, automated, and unified Batch CSV* data turbocharges your business intelligence, analytics, data visualization, SQL, or data science tools.
*Visit the Batch CSV docs for more product information. Need to chat? Talk with our data experts about Batch CSV.
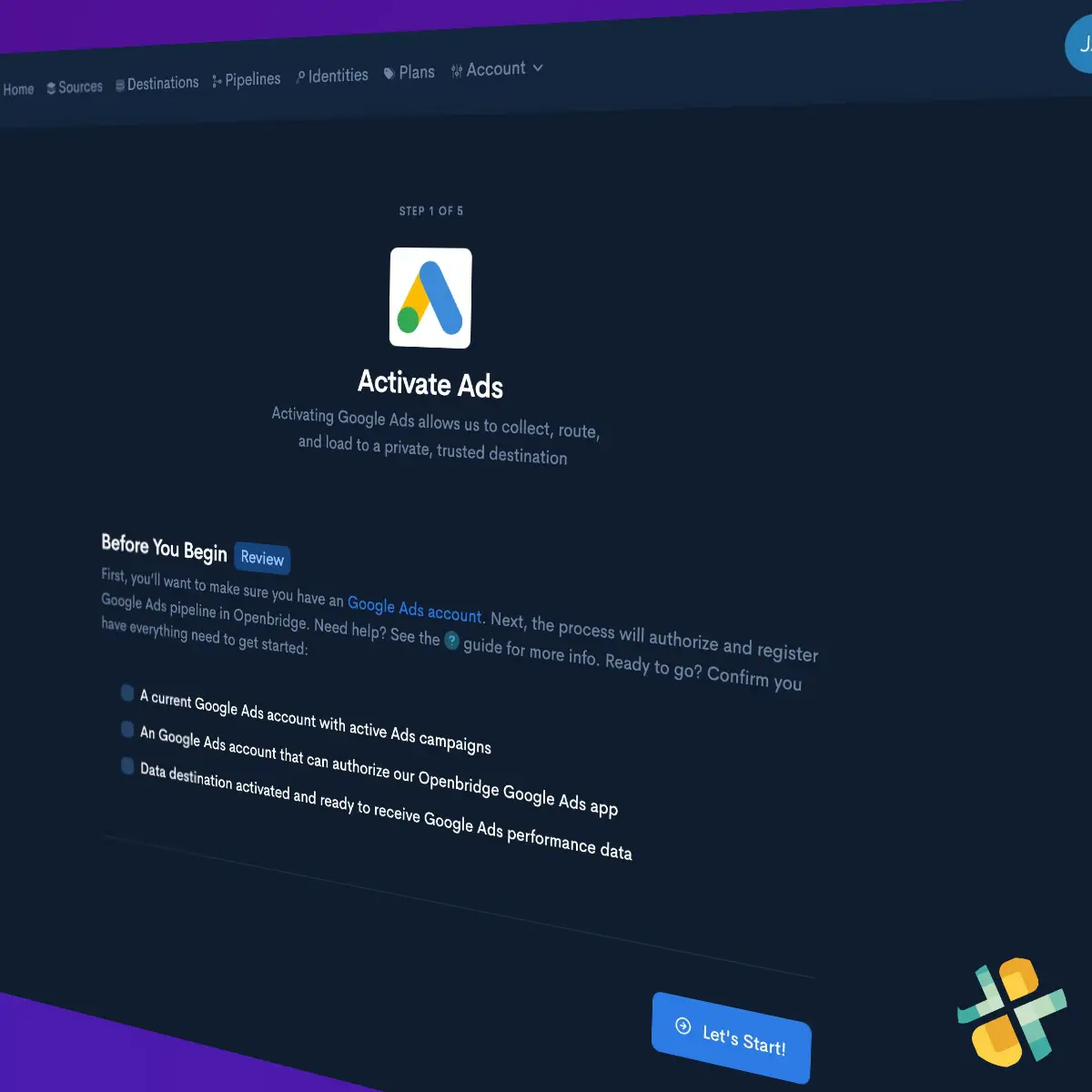
Step one
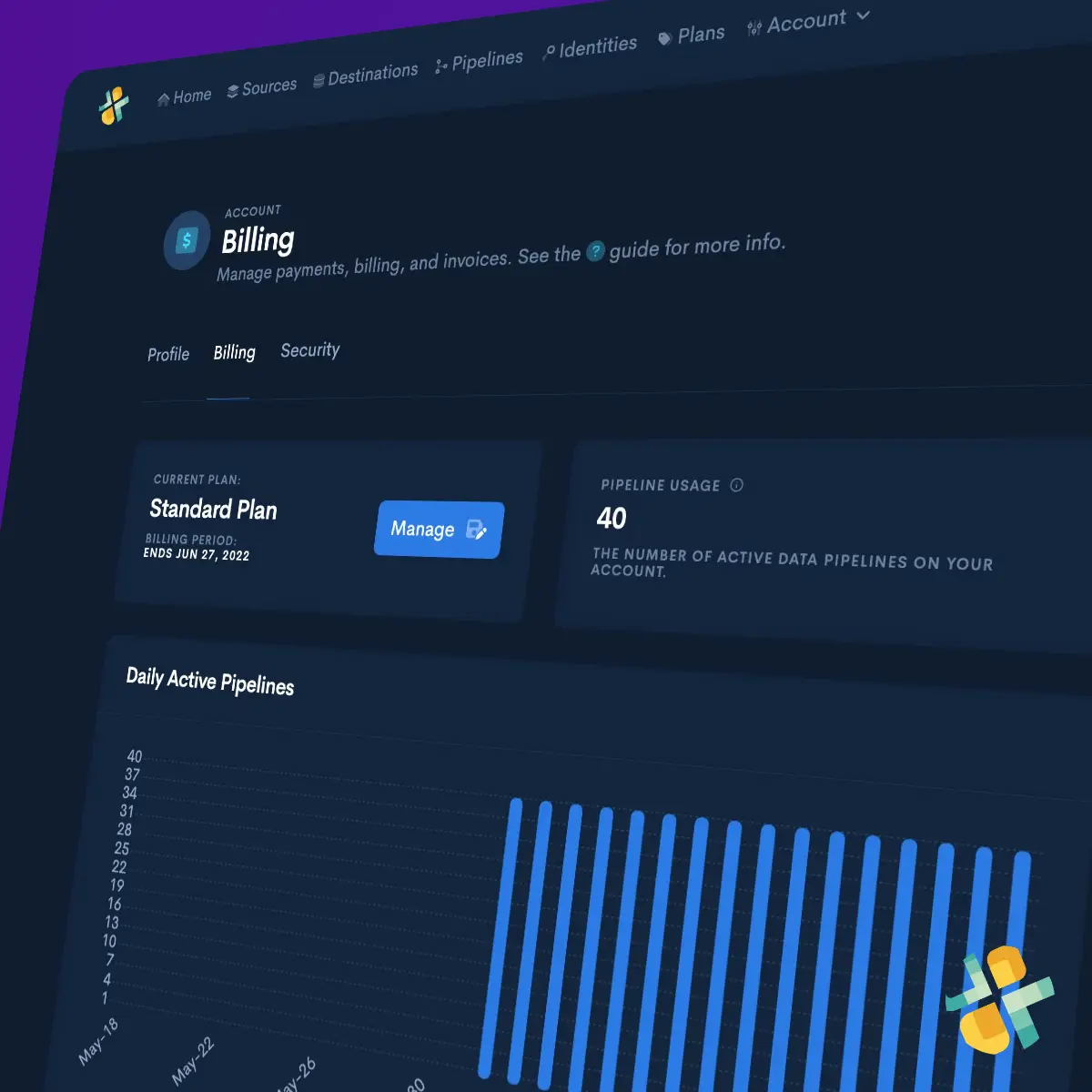
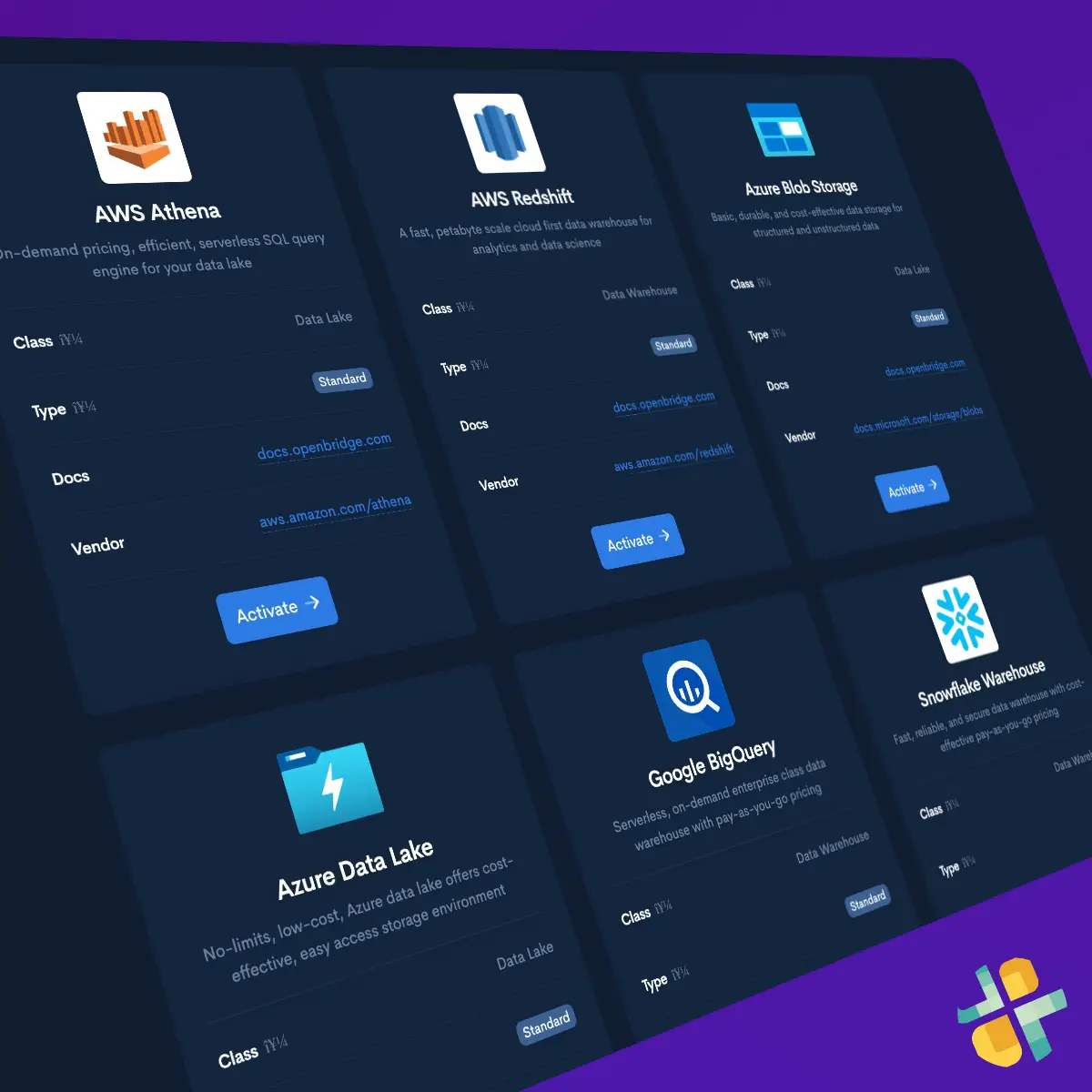
Create Data Destination
You can quickly create a private, trusted destination to store Batch CSV data using cloud data warehouses or data lakes like Databricks, Amazon Redshift, Amazon Redshift Spectrum, Google BigQuery, Snowflake, Azure Data Lake, and Amazon Athena.
See data destinationsStep Two
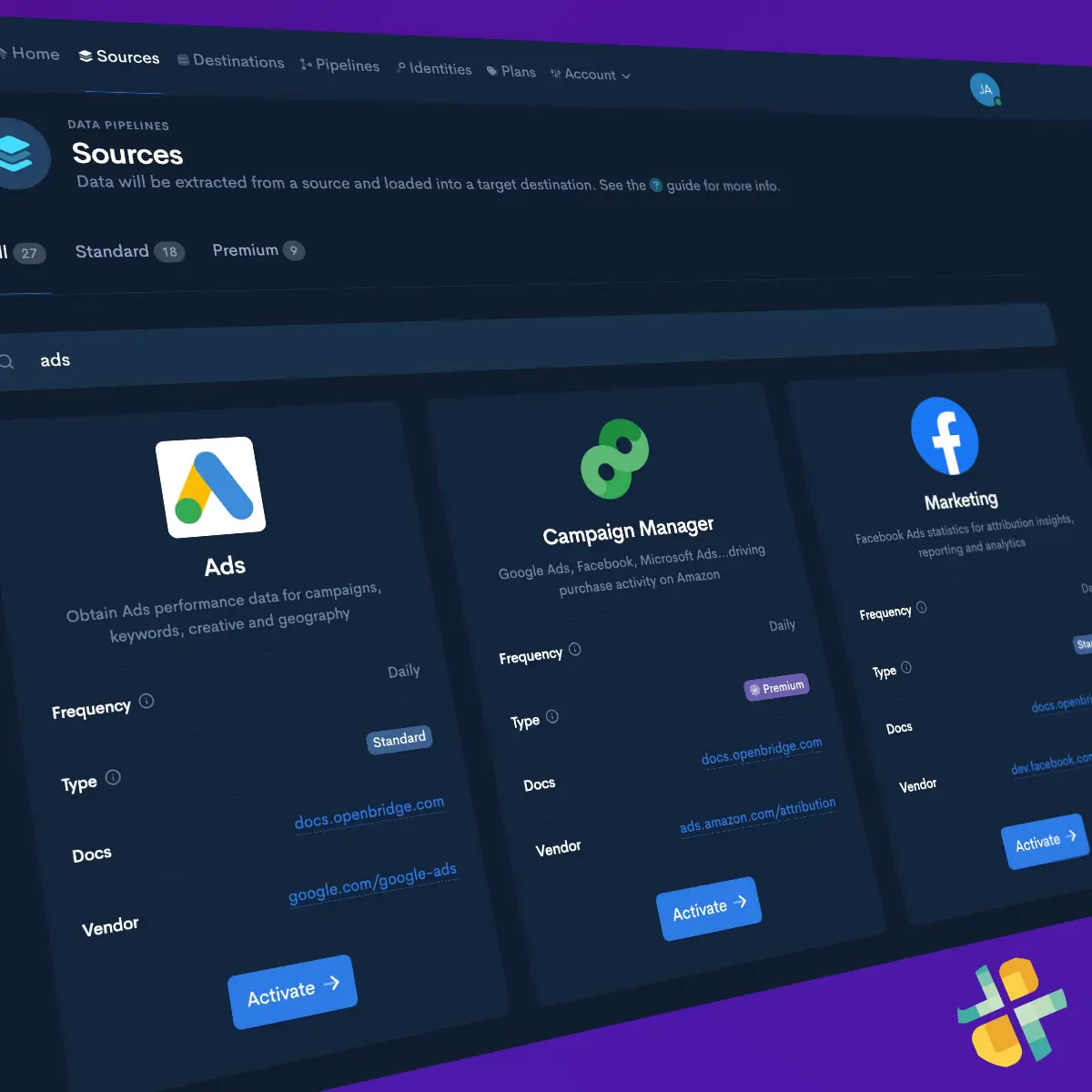
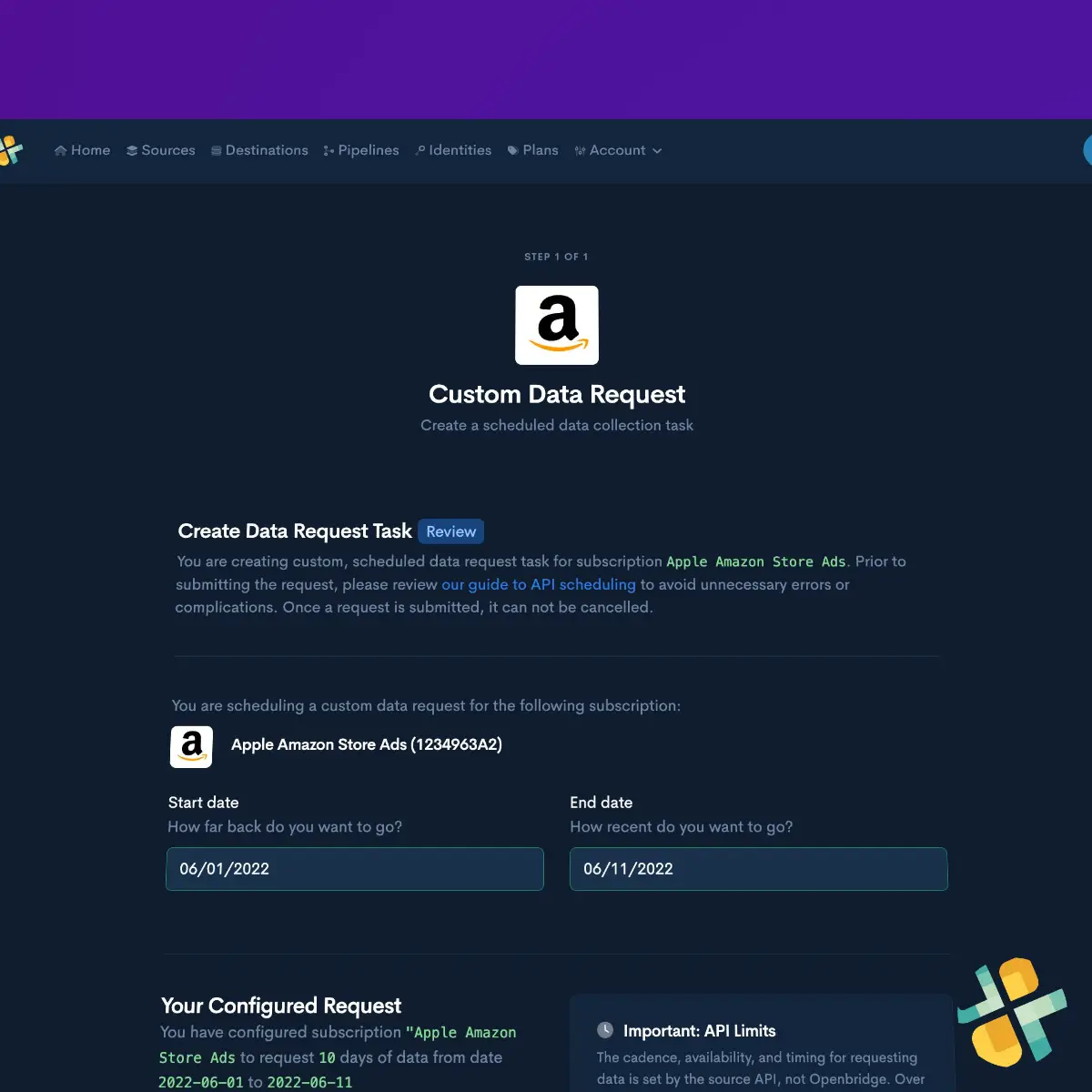
Activate Data Pipeline
Leveraging Batch CSV certified APIs , quickly and securely activate code-free, fully-automated data pipelines to a private, trusted data destination owned by you.
See integrationsStep Three
Explore Your Data
Unlocked Batch CSV data turbocharges the data tools you love to use like Tableau, Microsoft Power BI, Looker, Amazon QuickSight, Looker Studio, and many others with reliable, integrated data automation.
See data tools